What is Unicode?
Unicode is a computer standard that provides a single code for each character in each language, or each script, bearing in mind that a given script can be used by more than one language. To quote the Unicode site, “Unicode provides a unique number for every character, no matter what the platform, program, or language is”.
Encoding scripts
All of the data associated with a given script are contained in character code charts maintained by the Unicode Consortium. These charts, then, represent the character set of the script in question.
Here are the characters contained in Basic Latin, which is the first block of the Latin script in Unicode.
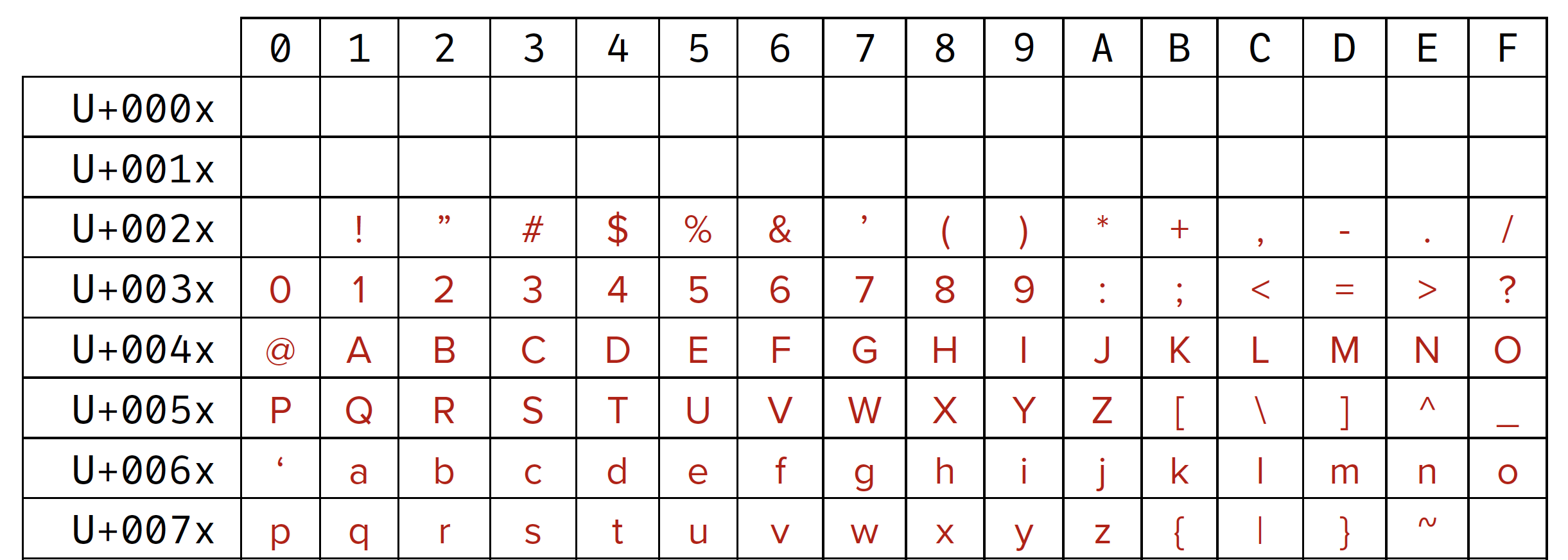
Basic Latin block in Unicode
This block contains the familar basic alphabet, and some punctuation and other characters. Note that this chart denotes each character’s code point in Unicode in hexadecimal form, a number system in base 16: 0–9, A–F.
Basic Latin begins at U+0020, which represents a space, and extends to U+007E, which is the tilde character.
Each and every character in Unicode has its unique hexadecimal reference in this form.
How is Unicode organized?
Unicode is made up of sixteen planes, with no characters assigned as of yet to planes 4 to 13.
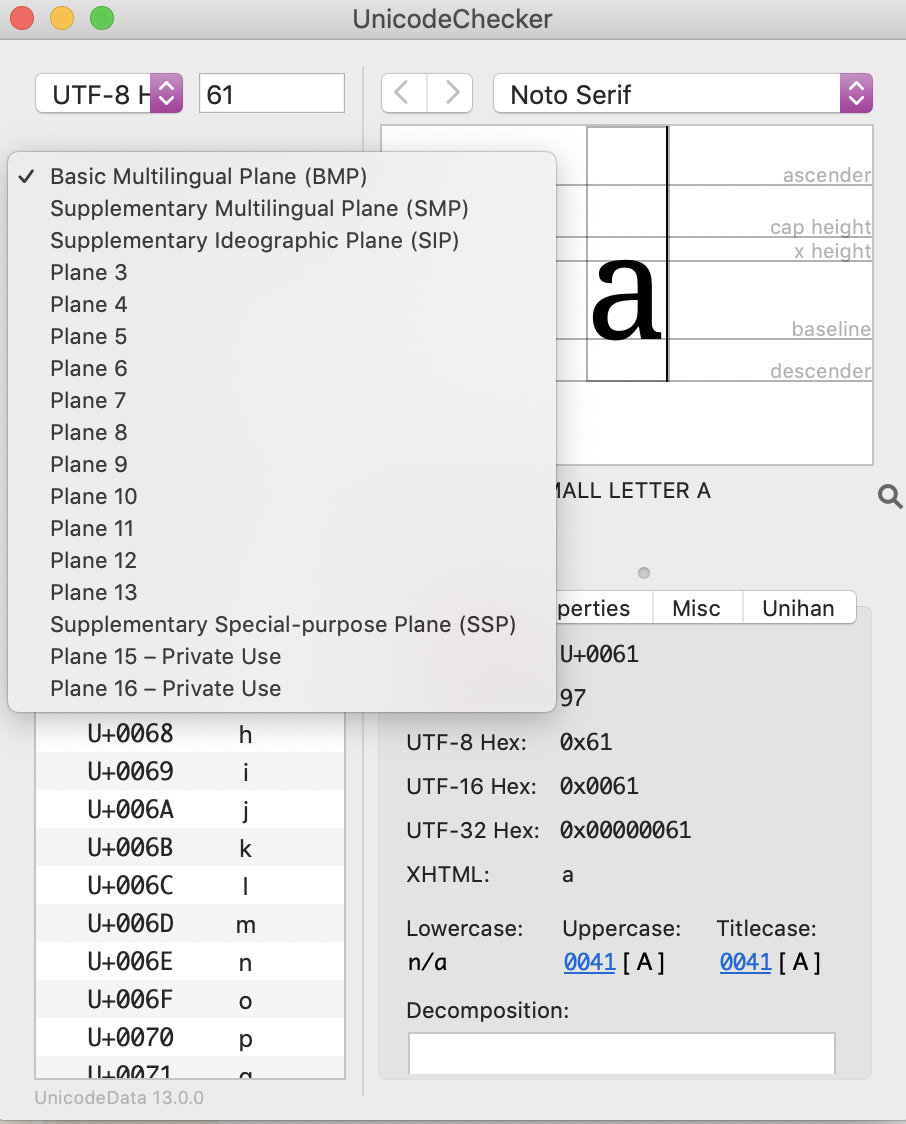
Unicode planes in UnicodeChecker
The Basic Multilingual Plane contains almost all modern languages, including those using the Latin, Arabic and CJK scripts, and also a large number of symbols.
The Supplementary Multilingual Plane contains historical scripts, for example, Egyptian hieroglypics.
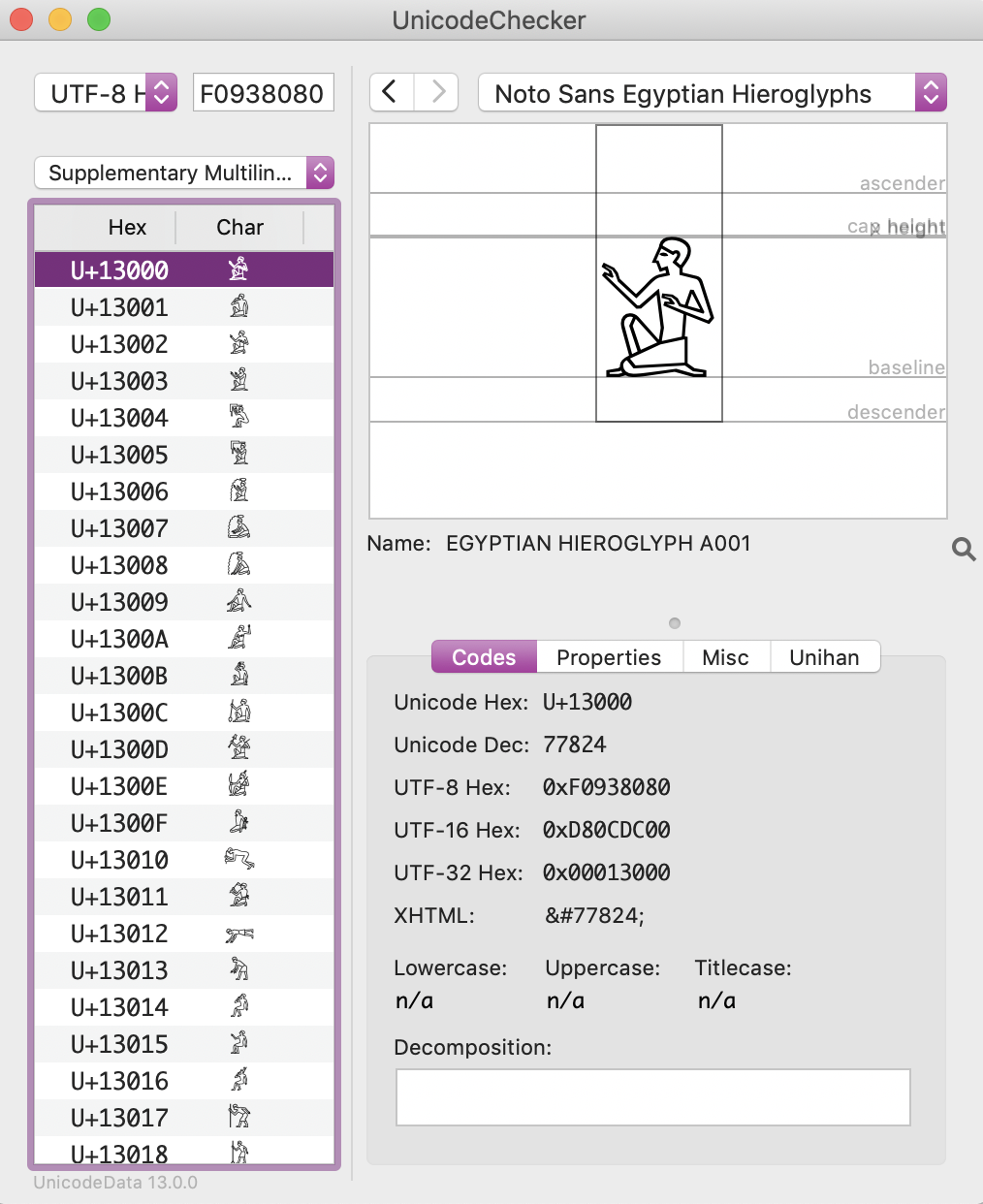
Egyptian hieroglyphic block in UnicodeChecker
The Supplementary Ideographic Plane includes CJK ideographs that have been added to more recent versions of Unicode.
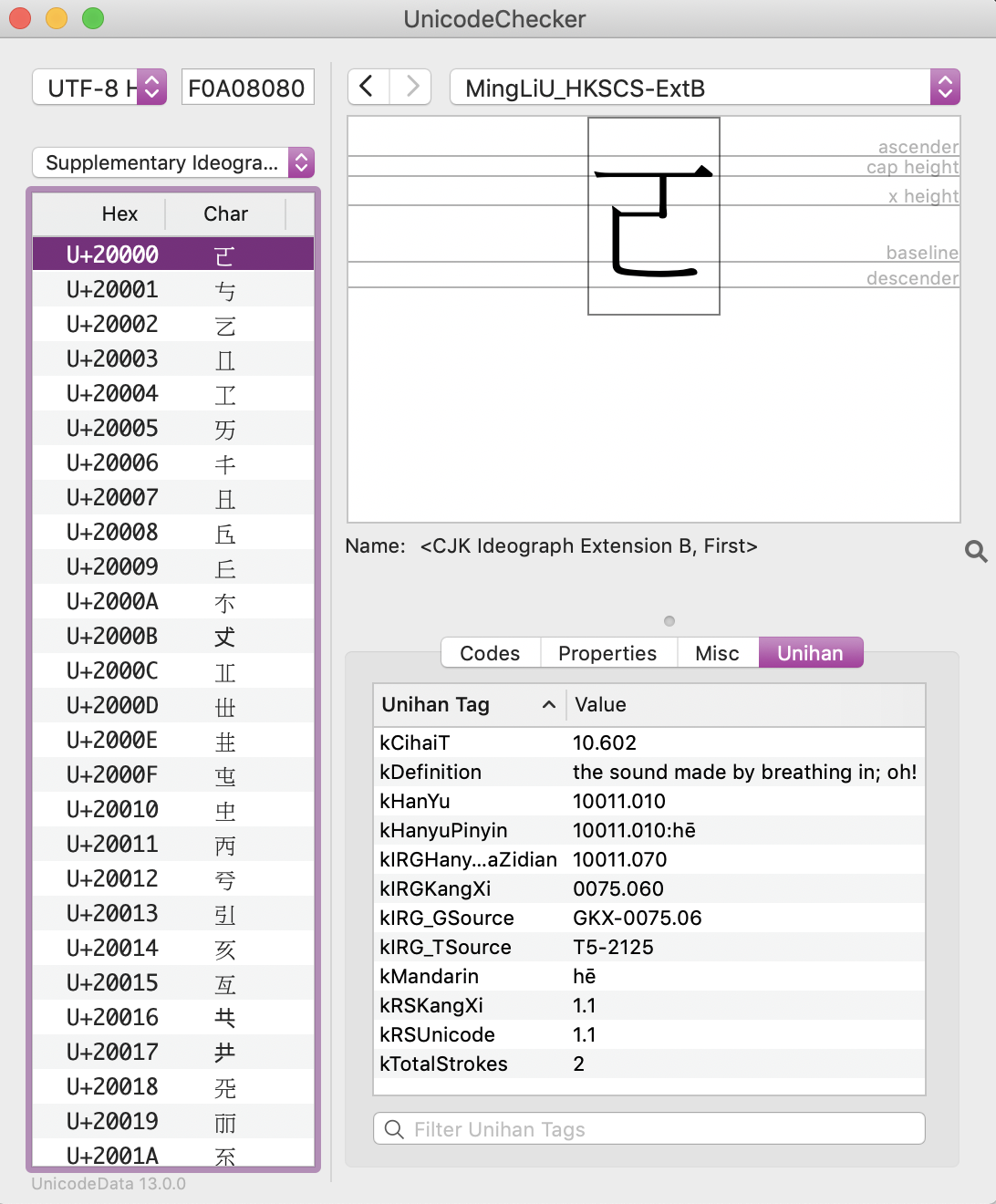
Supplementary Ideographic Plane in UnicodeChecker
Unicode blocks: the case of Latin script
Each plane in Unicode is made up of a number of blocks. Latin script, for instance, is made up of a total of 1286 characters in the Basic Multilingual Plane, divided into twelve blocks.
| Block | UniView | Unicode |
|---|---|---|
| Basic Latin | Character data | Character chart |
| Latin-1 Supplement | Character data | Character chart |
| Latin Extended-A | Character data | Character chart |
| Latin Extended-B | Character data | Character chart |
| Latin Extended-C | Character data | Character chart |
| Latin Extended-D | Character data | Character chart |
| Latin Extended-E | Character data | Character chart |
| Latin Extended Additional | Character data | Character chart |
| Halfwidth and Fullwidth Forms | Character data | Character chart |
| IPA Extensions | Character data | Character chart |
| Phonetic Extensions | Character data | Character chart |
| Phonetic Extensions Supplement | Character data | Character chart |
Here are the characters that make up the second of these blocks, Latin-1 Supplement.
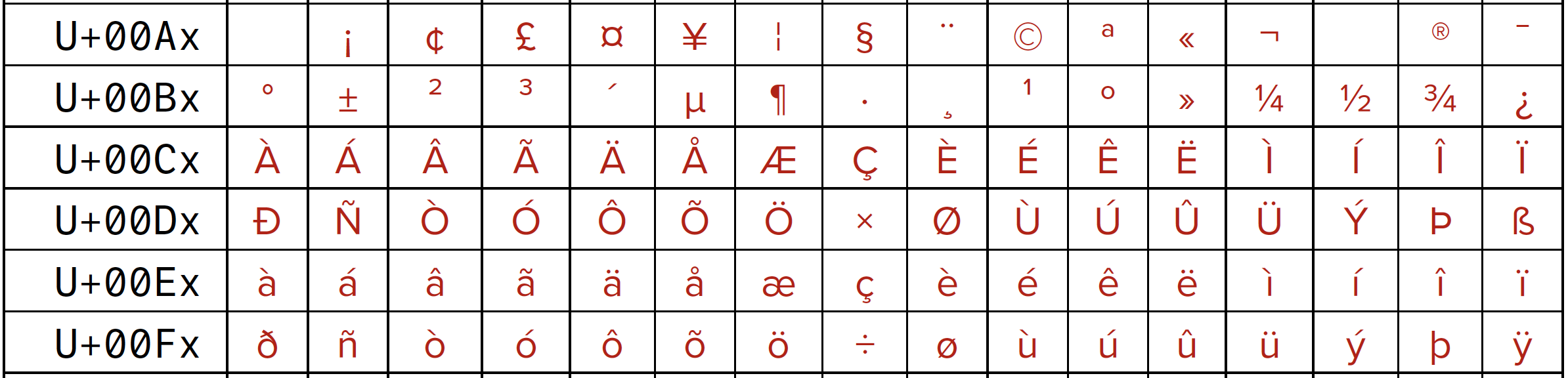
Latin-1 Supplement in the Basic Multilingual Plane
Unicode charts are now available in French as well as English, with the added possibility of searching for characters by name.
How computers handle characters
When you are working in a given application and select a character on a keyboard, you need to be sure that it will then appear on screen: you depend on a character encoding for this to happen.
The most common encoding used today is UTF-8. It is the standard encoding for the internet and is also the default in word-processing applications. When you enter a character in UTF-8, a computer will then transform that into binary code in bits, or minimal units of digital information (a 0 or a 1 in base 2 numbers).
For example, the character A in UTF-8 has the following value in binary code: 01000001.
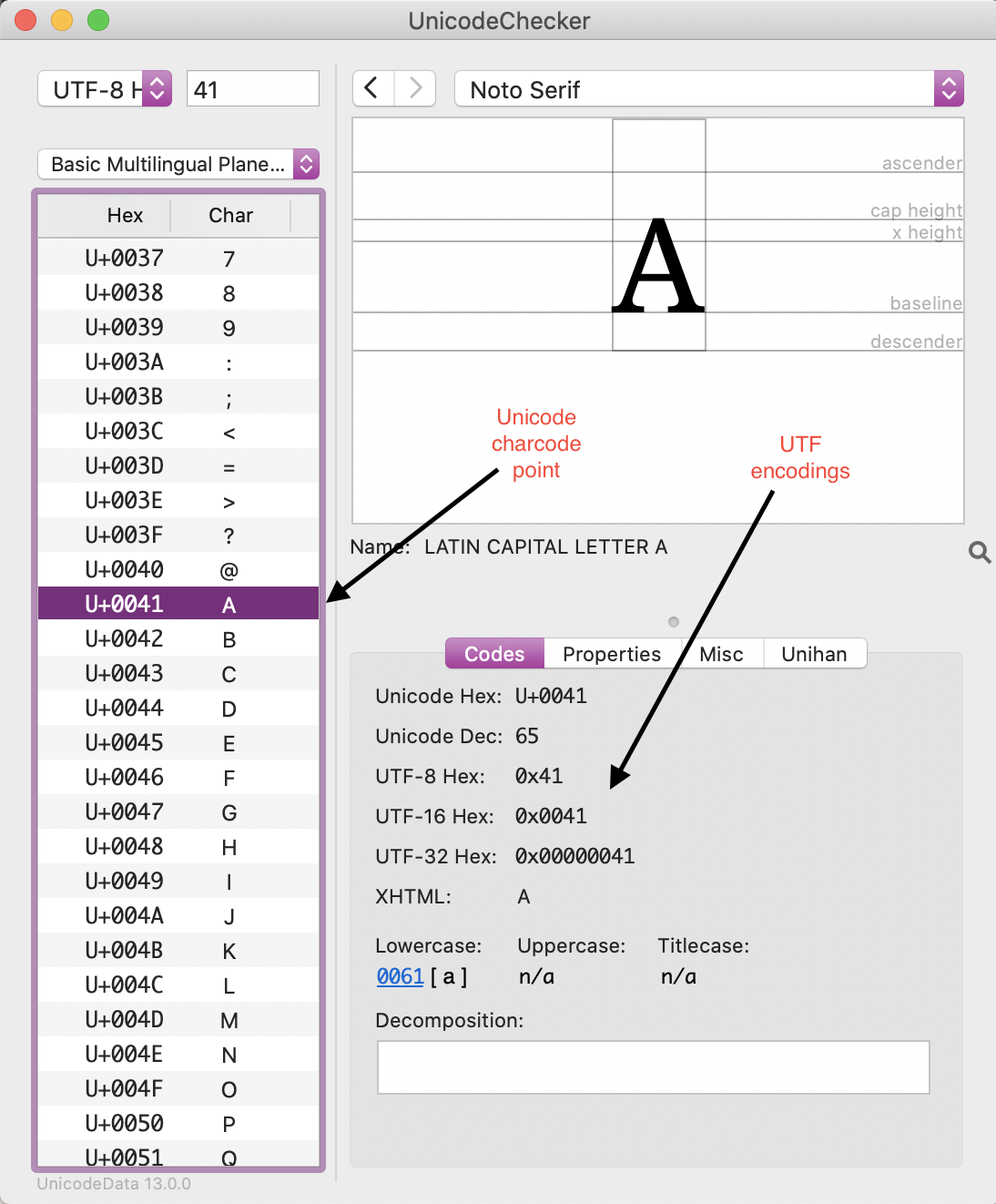
Unicode and UTF code points in UnicodeChecker
Here, you can see the familiar hexadecimal reference for upper-case a in Unicode. UTF-8 is one of three transformation formats, alongside UTF-16 and UTF-32. They differ according to the number of bytes, or units of 8 bits, they use to encode a character. UTF-8 uses between one and four 8-bit bytes; UTF-16 uses two bytes (that is, 16 bits at a minimum) or four bytes; UTF-32 uses four bytes to encode each character (that is, 32 bits).
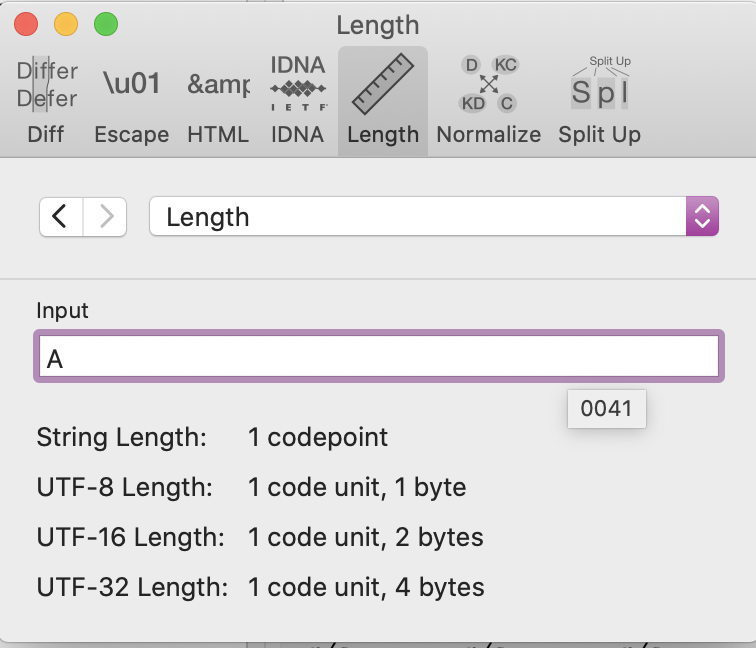
Code lengths in Unicode and in UTFs
Here again are some data for the upper-case character a. You can see that there is one codepoint or code unit in each case, but the number of bytes varies from one to four, with UTF-8 being the most economical format for simple characters in Latin script. This is one reason why today it is by far the most widely used encoding in the internet.
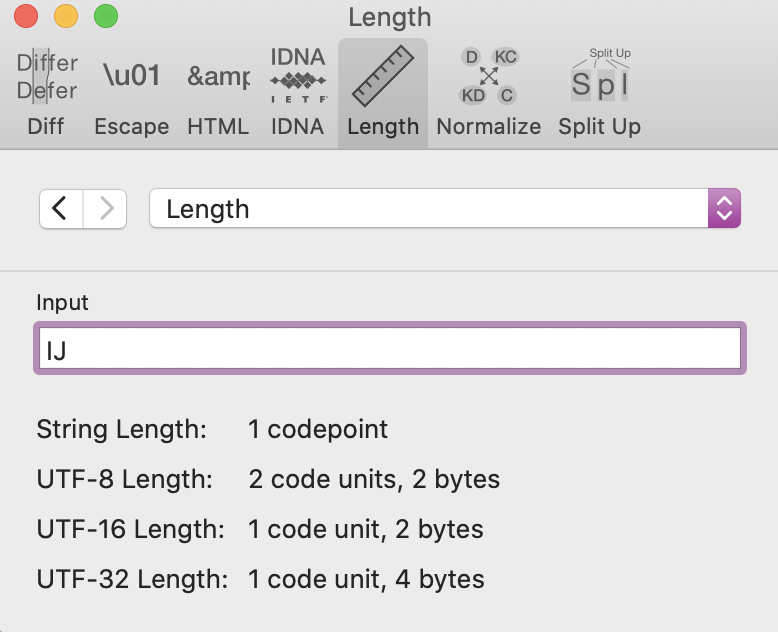
IJ: code length
By contrast, the upper-case ij digraph as used in Dutch represents a single code point and requires two bytes in UTF-8. An em-dash requires three bytes.
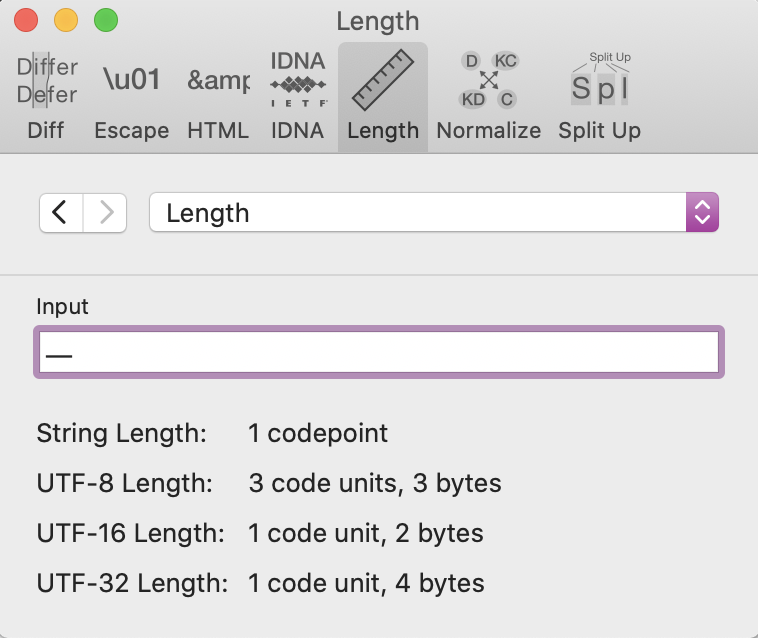
Em-dash: code length
CJK characters in UTF-8 are as a rule longer than those in Latin scripts.
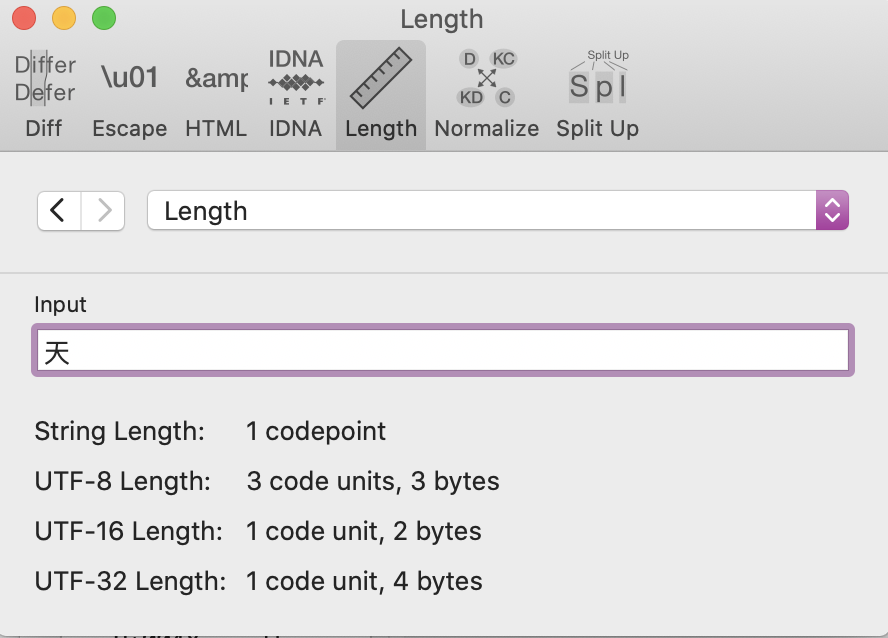
CJK character: code length
What, then, is the purpose of any of these transformation formats? It is to connect a Unicode reference-point to the purely binary encoding through which a computer operates.
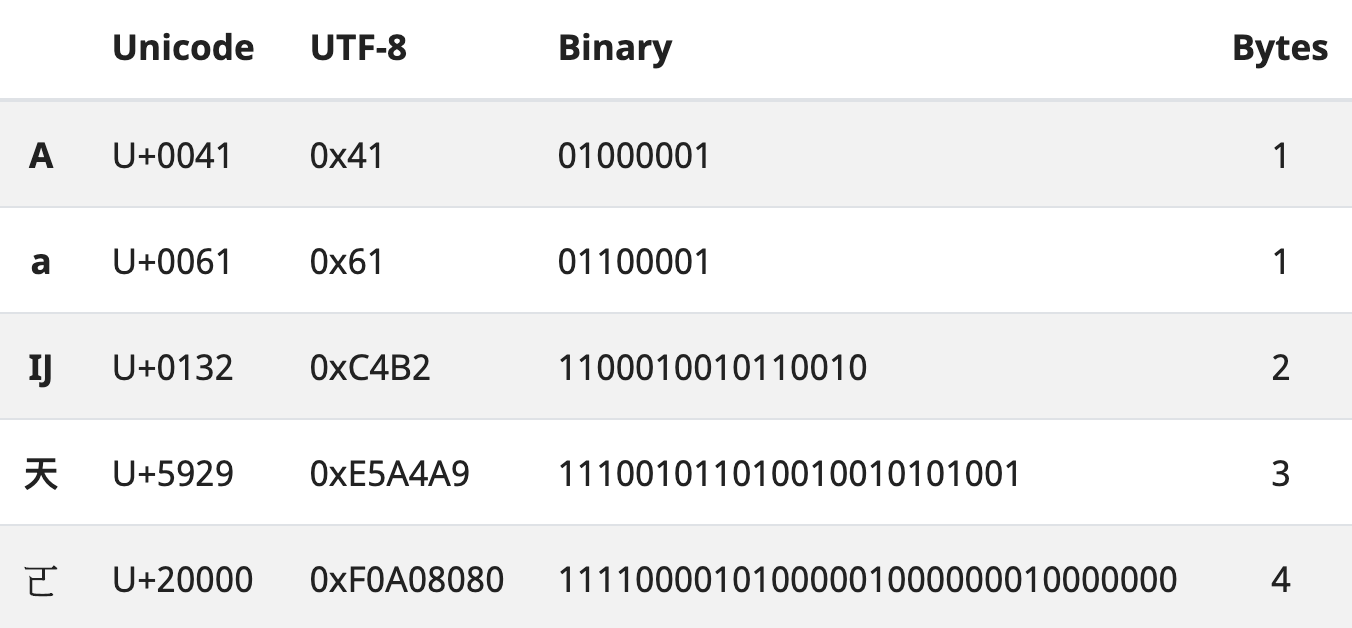
Translating code points between Unicode and binary
It is in binary format that the characters you type are ultimately stored in a computer — in other words, in bits and in turn in bytes. This explains what the size of a file, and all of the data it may contain in the form of numbers, formulae or text, is likewise expressed in bytes (e.g. kilobytes, megabytes).

File size in kilobytes (k)
Transformation formats such as UTF-8 can represent any character in Unicode, which means that you can expect to be able to input any character in any script in the course of your work. The existence of a single standard and a universal encoding like UTF-8 therefore greatly simplifies your work. UTF-8 values are also much easier to handle that plain binary code would be.