This is the multi-page printable view of this section. Click here to print.
Scripts and Unicode
- 1: What is a script?
- 2: What is Unicode?
- 3: Unicode tools
- 4: Using the International Phonetic Alphabet
1 - What is a script?
The written word is pervasive and scripts are the basis on which we communicate in writing. With the publication of Unicode 14.0.0 on 14 September 2021, the standard now supports 159 scripts.
This is how Unicode defines a script: “A collection of letters and other written signs used to represent textual information in one or more writing systems. For example, Russian is written with a subset of the Cyrillic script; Ukrainian is written with a different subset. The Japanese writing system uses several scripts” (Glossary of Unicode terms). Within this framework, the different scripts in the world, historical and contemporary, present wide variations.
About two-thirds of the writing systems in the world today use alphabetical scripts
Latin script
This is the script that you are likely to use most often: it is the one in which English and many European languages are written, and is the most widely script used today.
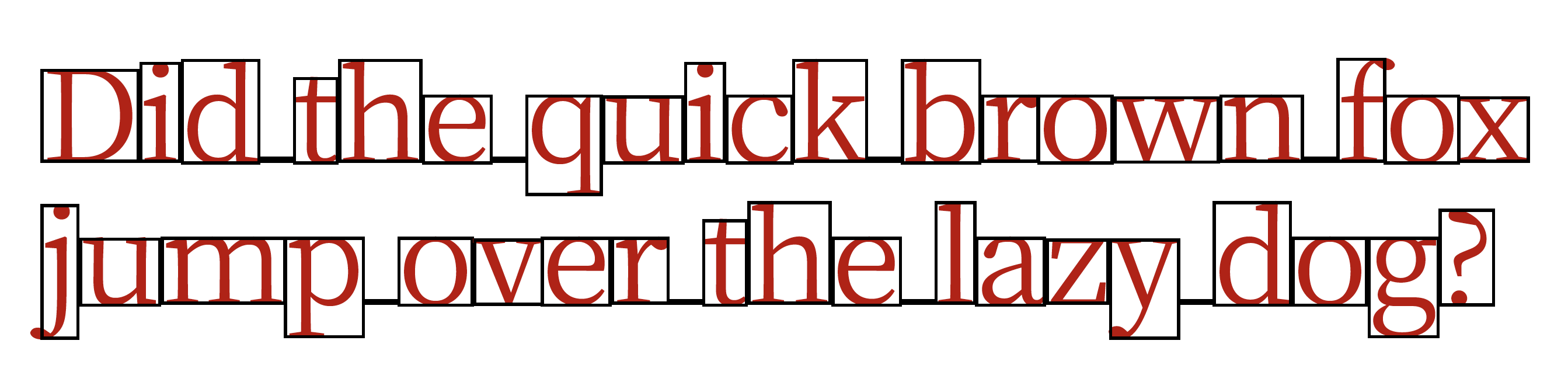
Latin script features
Scripts can be defined according to a number of characteristics, using Unicode or typographical terminology. Here are a number of these characteristics in the case of Latin script:
- Latin script is alphabetical
- it is bicameral, meaning that it has upper-case and lower-case characters, and is case-sensitive — so, we recognize brown to be an adjective and Brown to be a proper noun
- it is a left-to-right script
- it uses spaces as word-separators
- Latin script uses hyphenation
- Latin script uses what is termed a mid-baseline, with some characters having elements that descend below the base
- Latin script has what are termed its own native digits, or numerals
You can see in the example above that the character d is used it its upper case form. The bounding boxes allow us to see that words are separated by spaces and that some characters, for example, d, h, k, b and f, have ascenders, or parts of the character that extend about what is termed the script’s x-height. Likewise, j, p, y and g have descenders. Note too that the interrogation mark extends about x-height.
Arabic script

Arabic script
Arabic scripts present several more distinguishing features than Latin script. After the Latin alphabet, it is the second most widely used script in the world.
- Arabic is a right-to-left mid-baseline script
- the script directly represents only consonants and long vowel sounds; in other words, it is an abjad
- short vowel sounds and other phonetic information are denoted by diacritics
- it is a cursive script; in other words, the characters “join up”
- the shape of cursive characters can be determined by the characters to which they are joined
- characters can also overlap
- unlike Latin script, it is not case-sensitive
- like Latin script, it has native digits
- spaces are used as word-separators
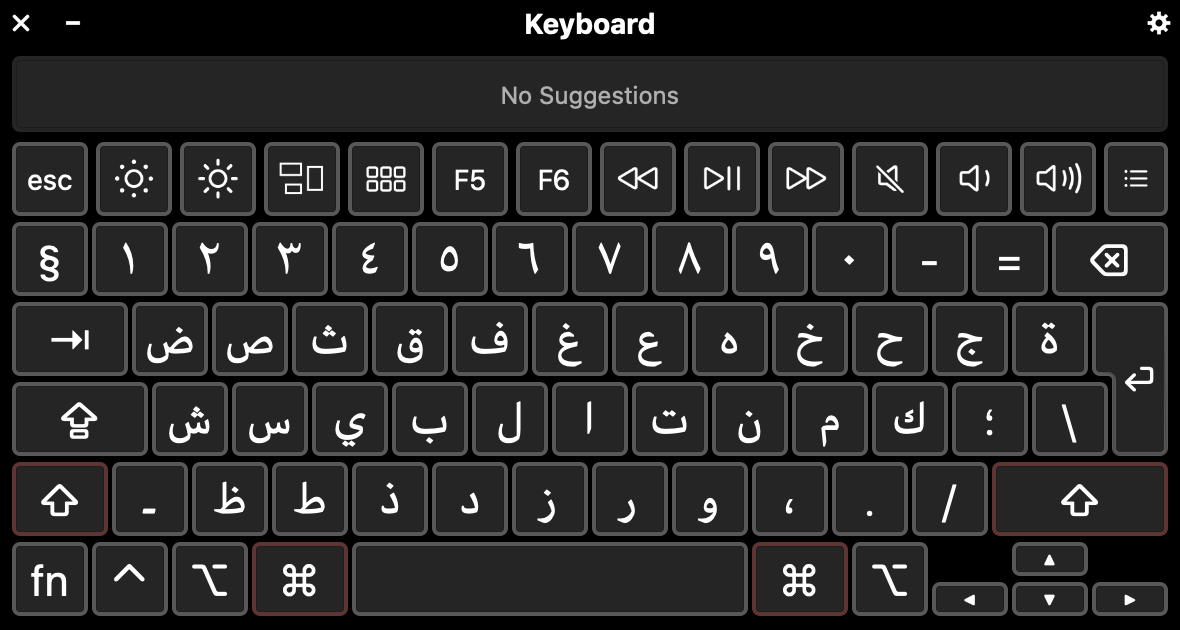
An Arabic keyboard
Note the Arabic numerals on the second row from the top of this lower case keyboard.
CJK scripts
CJK scripts refer to Chinese, or Han, ideographs used in the writing systems of Chinese and Japanese, and to a more limited extent in Korean. Unicode supports more than eighty thousand Han characters.
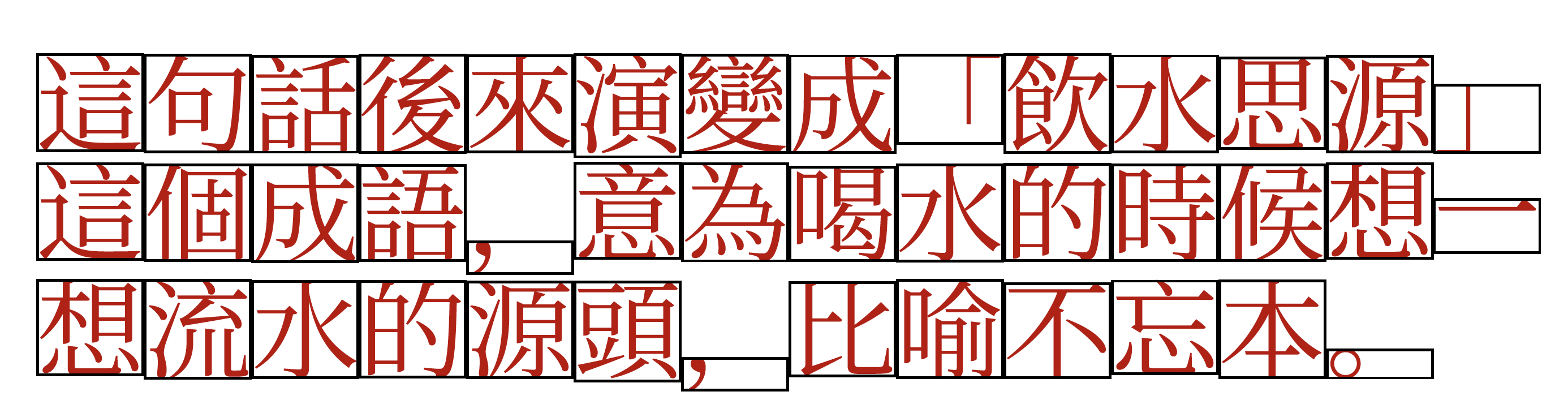
Here is an example of a sentence using the Simplified Chinese script.

CJK: Simplified Chinese
Can you identify the use of Traditional Chinese quotation marks here, as well as the European comma and full point?
- Han scripts are ideographic, with characters usually representing a spoken syllable
- for this reason, Han script is also referred to as a logosyllabary
- Japanese script features both syllabic and ideographic-syllabic text, with word-spacing being used with the former
- CJK scripts generally are left-to-right and can also be written vertically
- they are not case-sensitive
- Han does not use spaces as word-separators, though the justification of lines leads to adjustments in the placement of characters within their frames
- Korean, by contrast, does feature spacing between words
- both Han and Japanese script uses a centred baseline, whereas in Korean a bottom baseline is used
Han: case and boundaries
A Han ideogram can be thought of as contained a uniform square frame: here, the characters are displayed in visible bounding boxes to illustrate the absence of features like case and word separation. Note that punctuation marks imported from European scripts are full-width rather than half-width, and therefore do not require additional spacing.
A historical script: Ogham
Unicode extends also to historical scripts that are no longer current, one example being the medieval script of Ogham, which was widely used for inscriptions in Ireland, and also in parts of Britain. Here is an example of an Ogham inscription.

An inscription in Ogham
- Ogham is an alphabetical script, with incisions corresponding to characters in the Latin alphabet
- it is a left-to-right script, with a mid-baseline
- many original Ogham inscriptions are vertical, reading from bottom to top, as in this example
- Ogham inscriptions did not make use of word-spacing
- Ogham forms a block in the Basic Multilingual Plane in Unicode
- the Noto Project includes a font for Ogham
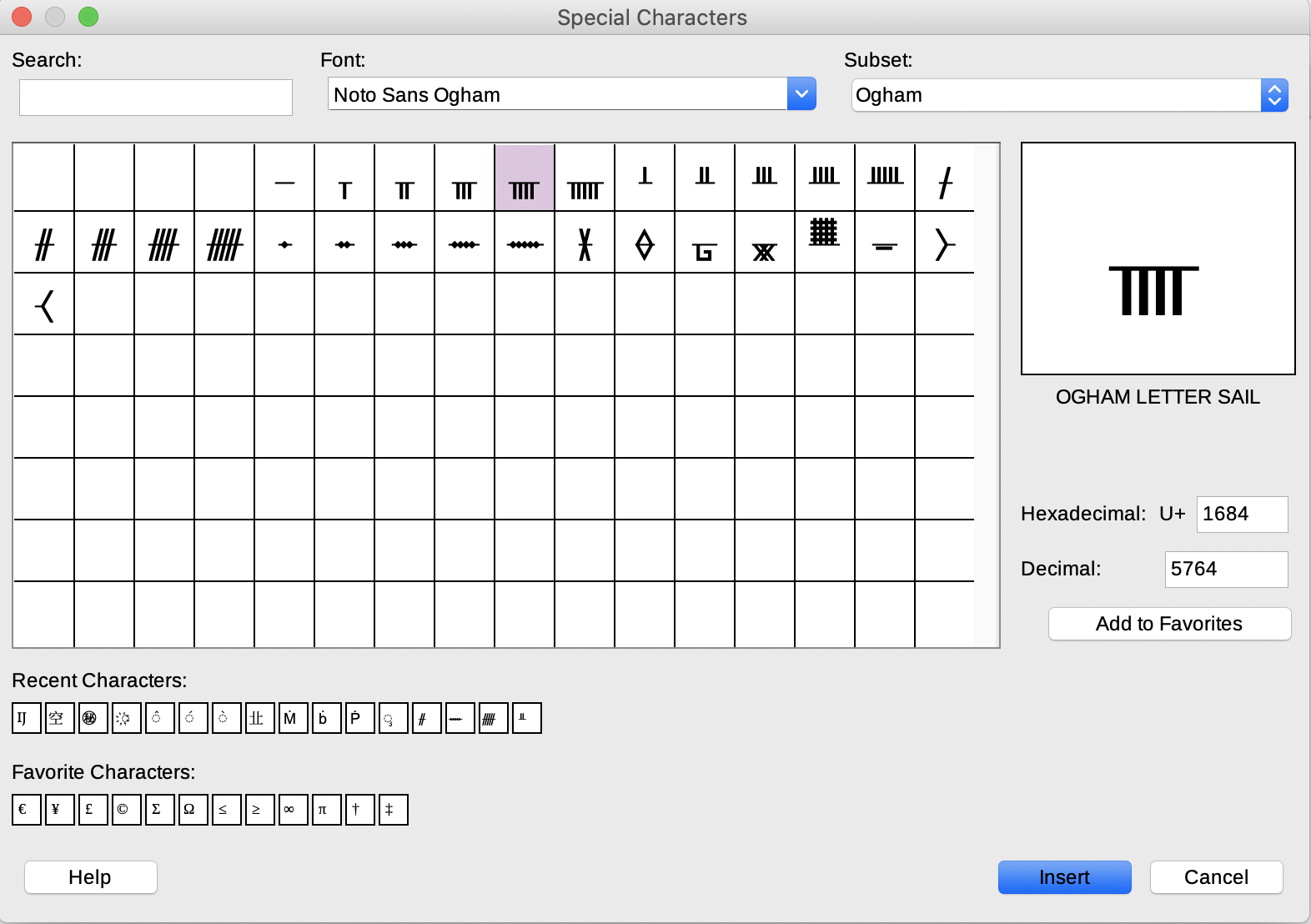
Inserting an Ogham character in LibreOffice
2 - What is Unicode?
Unicode is a computer standard that provides a single code for each character in each language, or each script, bearing in mind that a given script can be used by more than one language. To quote the Unicode site, “Unicode provides a unique number for every character, no matter what the platform, program, or language is”.
Encoding scripts
All of the data associated with a given script are contained in character code charts maintained by the Unicode Consortium. These charts, then, represent the character set of the script in question.
Here are the characters contained in Basic Latin, which is the first block of the Latin script in Unicode.
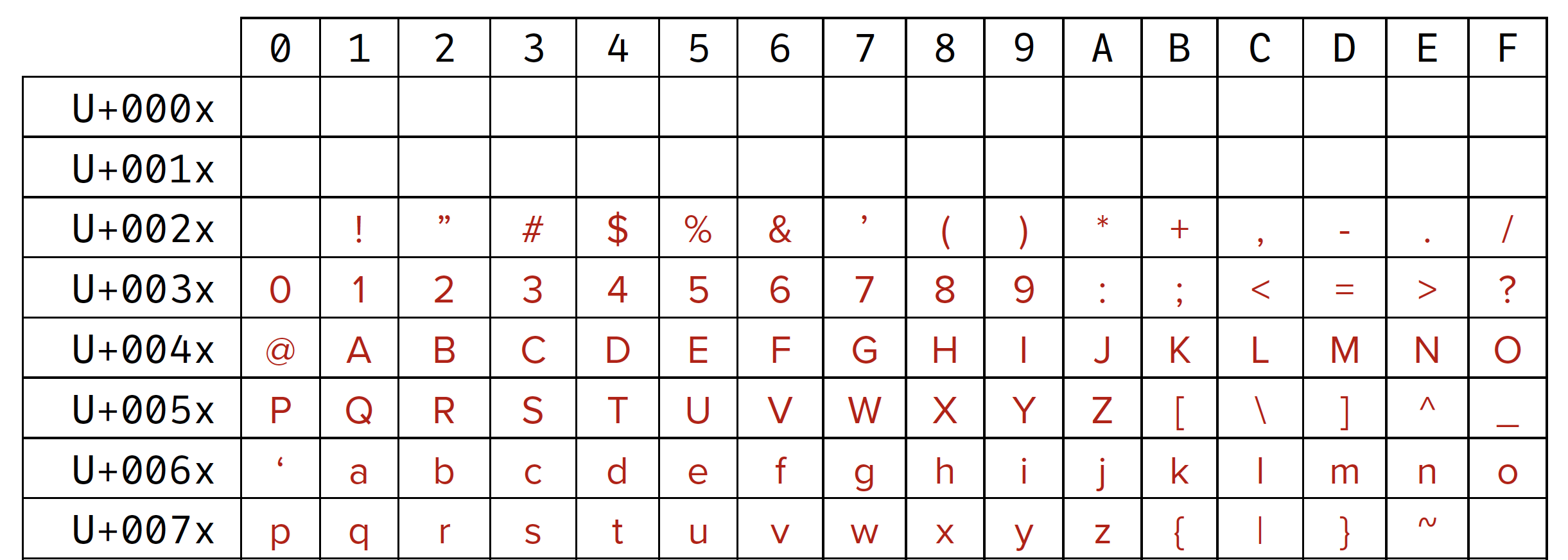
Basic Latin block in Unicode
This block contains the familar basic alphabet, and some punctuation and other characters. Note that this chart denotes each character’s code point in Unicode in hexadecimal form, a number system in base 16: 0–9, A–F.
Basic Latin begins at U+0020, which represents a space, and extends to U+007E, which is the tilde character.
Each and every character in Unicode has its unique hexadecimal reference in this form.
How is Unicode organized?
Unicode is made up of sixteen planes, with no characters assigned as of yet to planes 4 to 13.
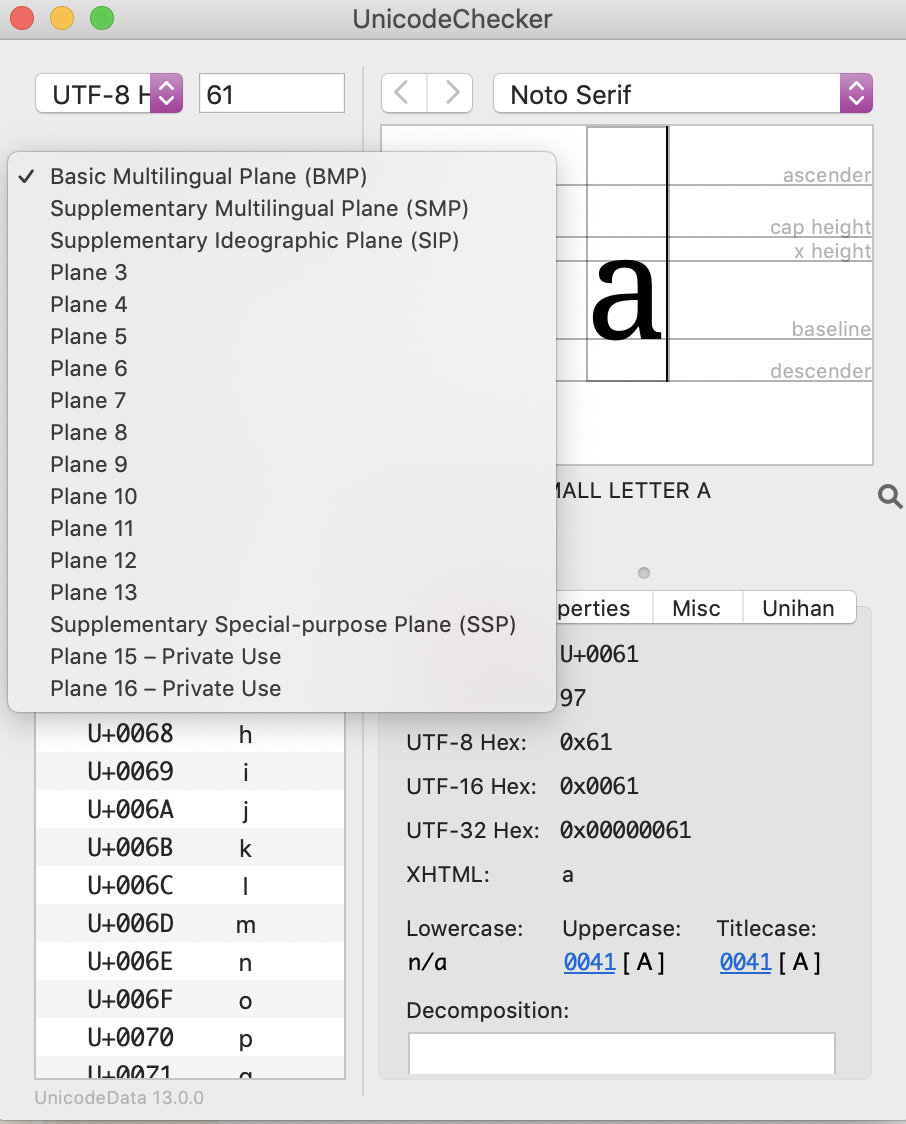
Unicode planes in UnicodeChecker
The Basic Multilingual Plane contains almost all modern languages, including those using the Latin, Arabic and CJK scripts, and also a large number of symbols.
The Supplementary Multilingual Plane contains historical scripts, for example, Egyptian hieroglypics.
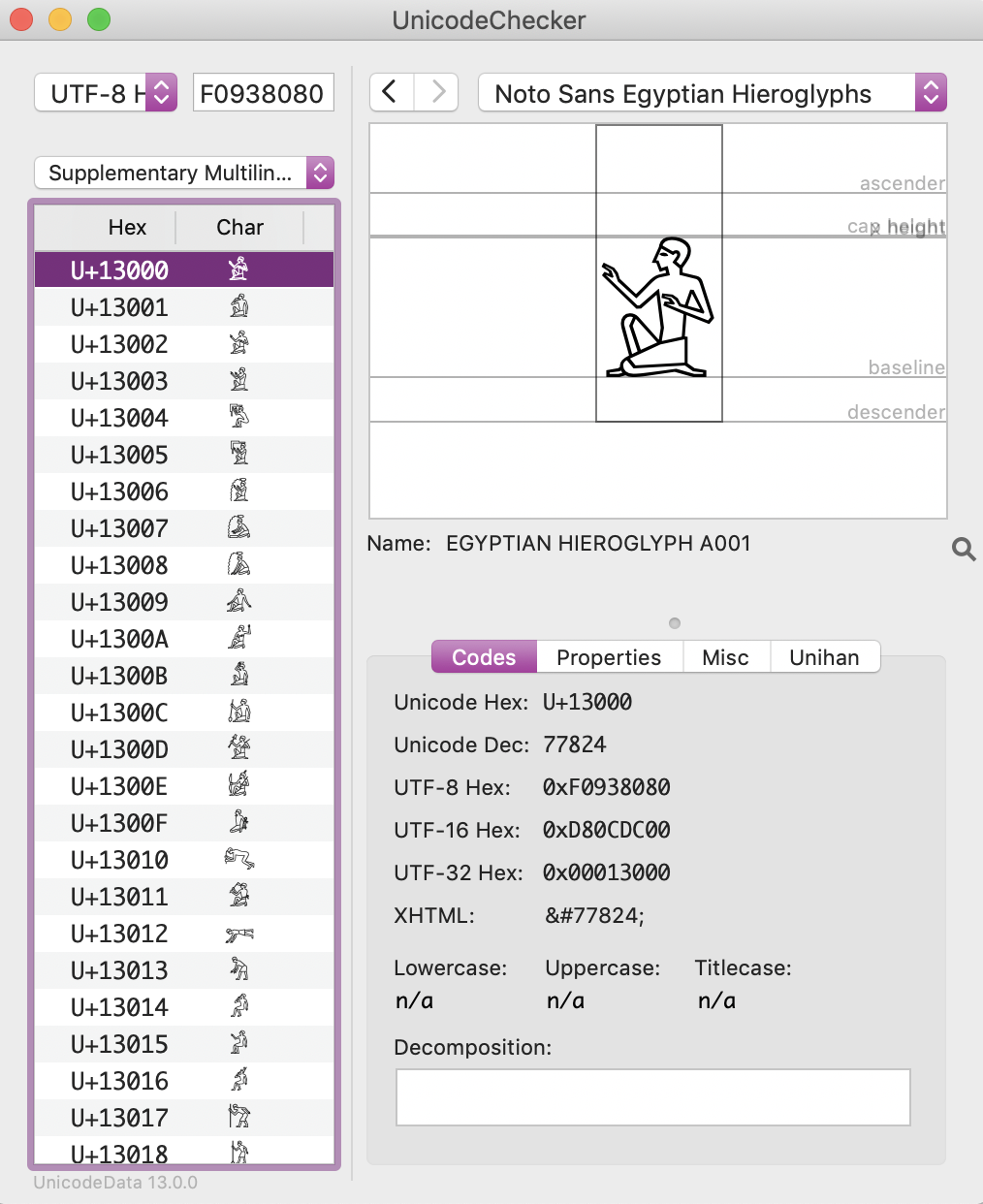
Egyptian hieroglyphic block in UnicodeChecker
The Supplementary Ideographic Plane includes CJK ideographs that have been added to more recent versions of Unicode.
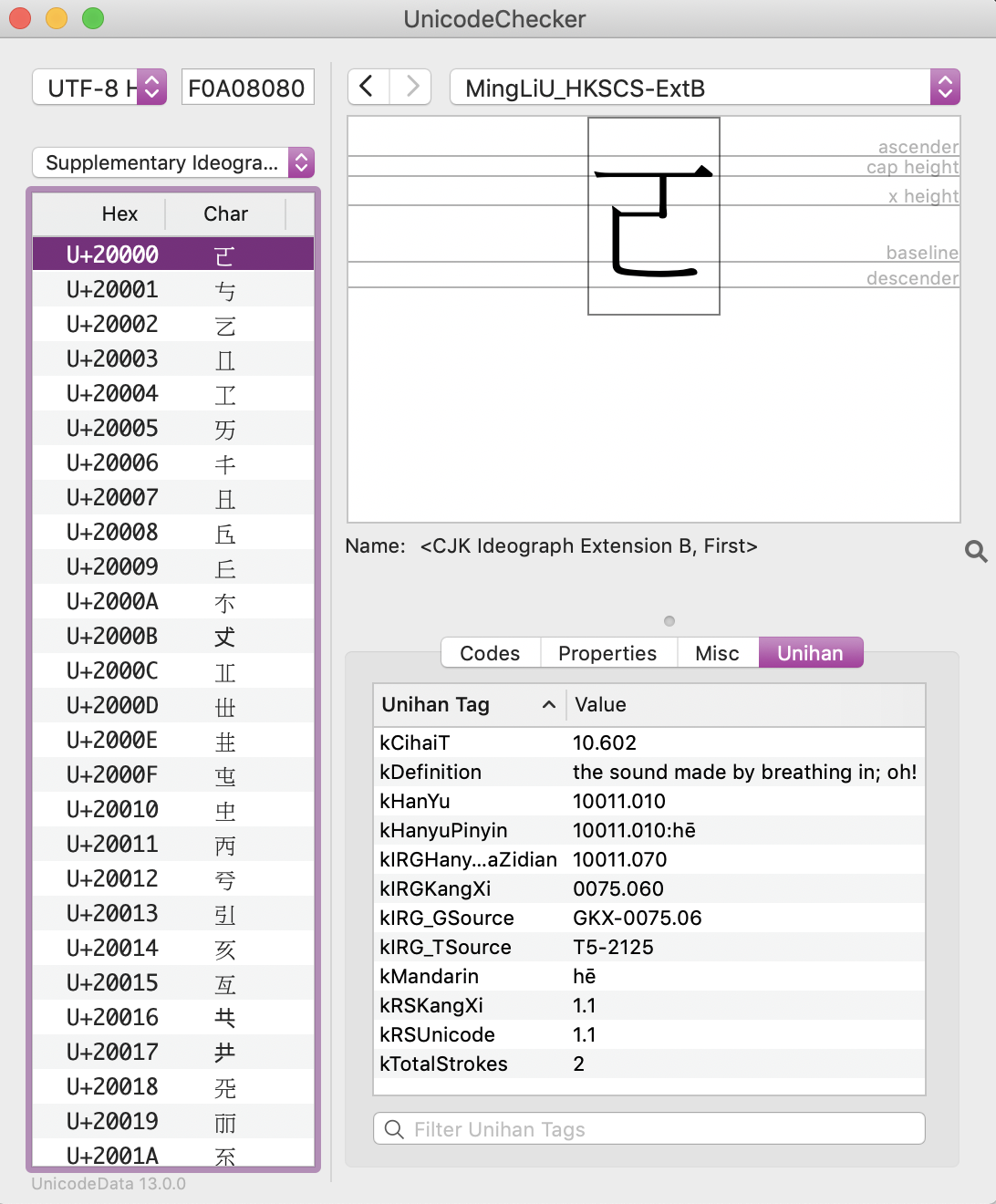
Supplementary Ideographic Plane in UnicodeChecker
Unicode blocks: the case of Latin script
Each plane in Unicode is made up of a number of blocks. Latin script, for instance, is made up of a total of 1286 characters in the Basic Multilingual Plane, divided into twelve blocks.
| Block | UniView | Unicode |
|---|---|---|
| Basic Latin | Character data | Character chart |
| Latin-1 Supplement | Character data | Character chart |
| Latin Extended-A | Character data | Character chart |
| Latin Extended-B | Character data | Character chart |
| Latin Extended-C | Character data | Character chart |
| Latin Extended-D | Character data | Character chart |
| Latin Extended-E | Character data | Character chart |
| Latin Extended Additional | Character data | Character chart |
| Halfwidth and Fullwidth Forms | Character data | Character chart |
| IPA Extensions | Character data | Character chart |
| Phonetic Extensions | Character data | Character chart |
| Phonetic Extensions Supplement | Character data | Character chart |
Here are the characters that make up the second of these blocks, Latin-1 Supplement.
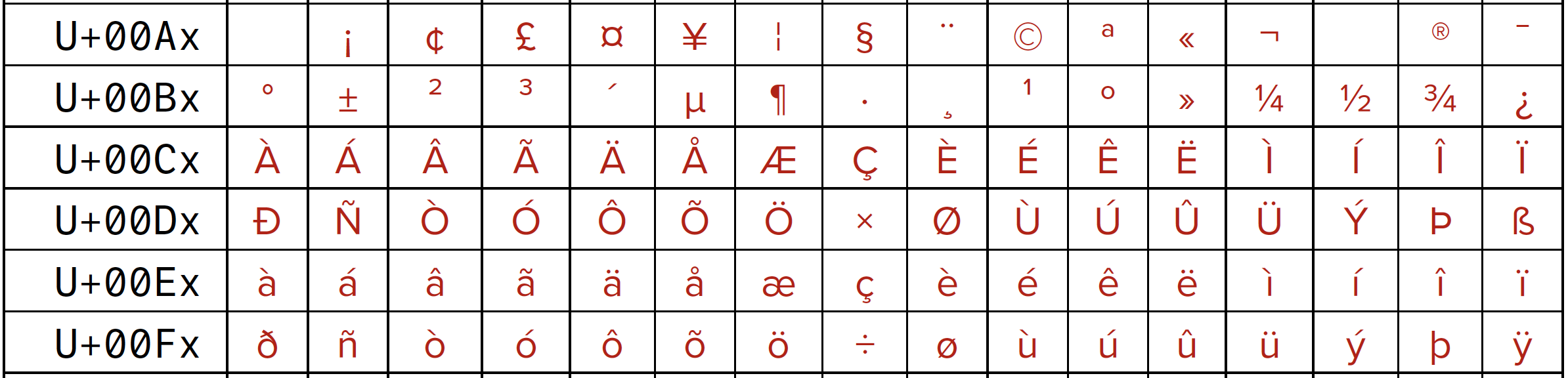
Latin-1 Supplement in the Basic Multilingual Plane
Unicode charts are now available in French as well as English, with the added possibility of searching for characters by name.
How computers handle characters
When you are working in a given application and select a character on a keyboard, you need to be sure that it will then appear on screen: you depend on a character encoding for this to happen.
The most common encoding used today is UTF-8. It is the standard encoding for the internet and is also the default in word-processing applications. When you enter a character in UTF-8, a computer will then transform that into binary code in bits, or minimal units of digital information (a 0 or a 1 in base 2 numbers).
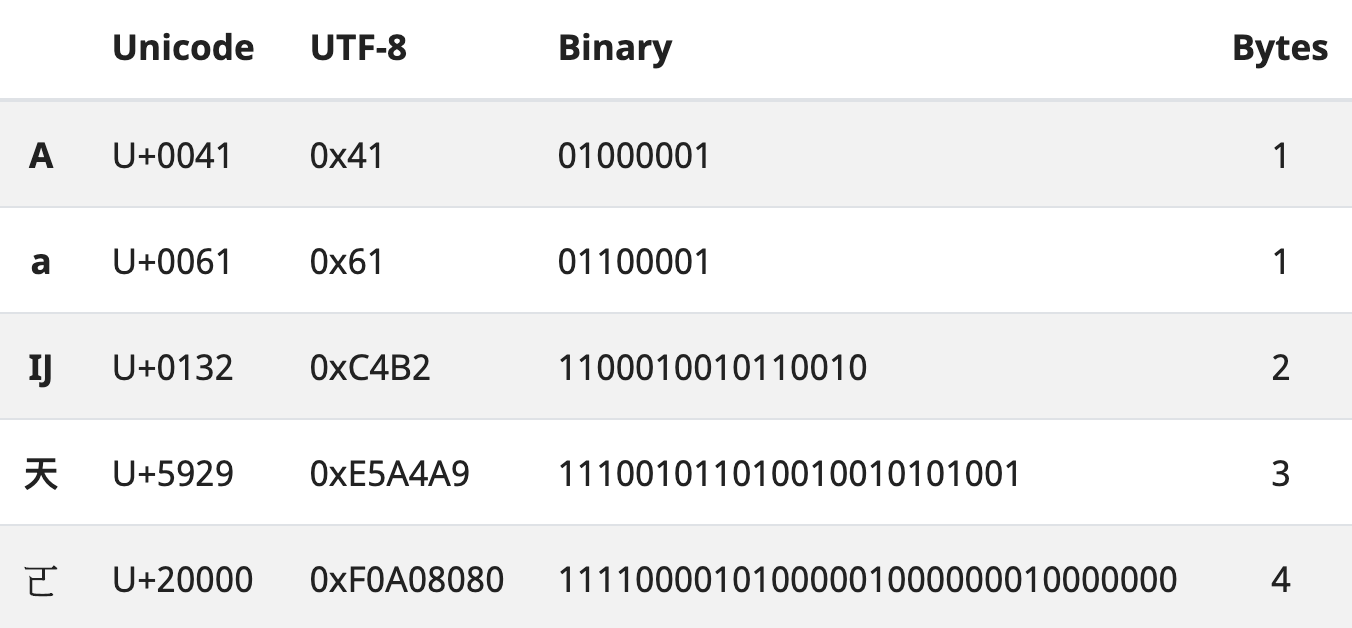
For example, the character A in UTF-8 has the following value in binary code: 01000001.
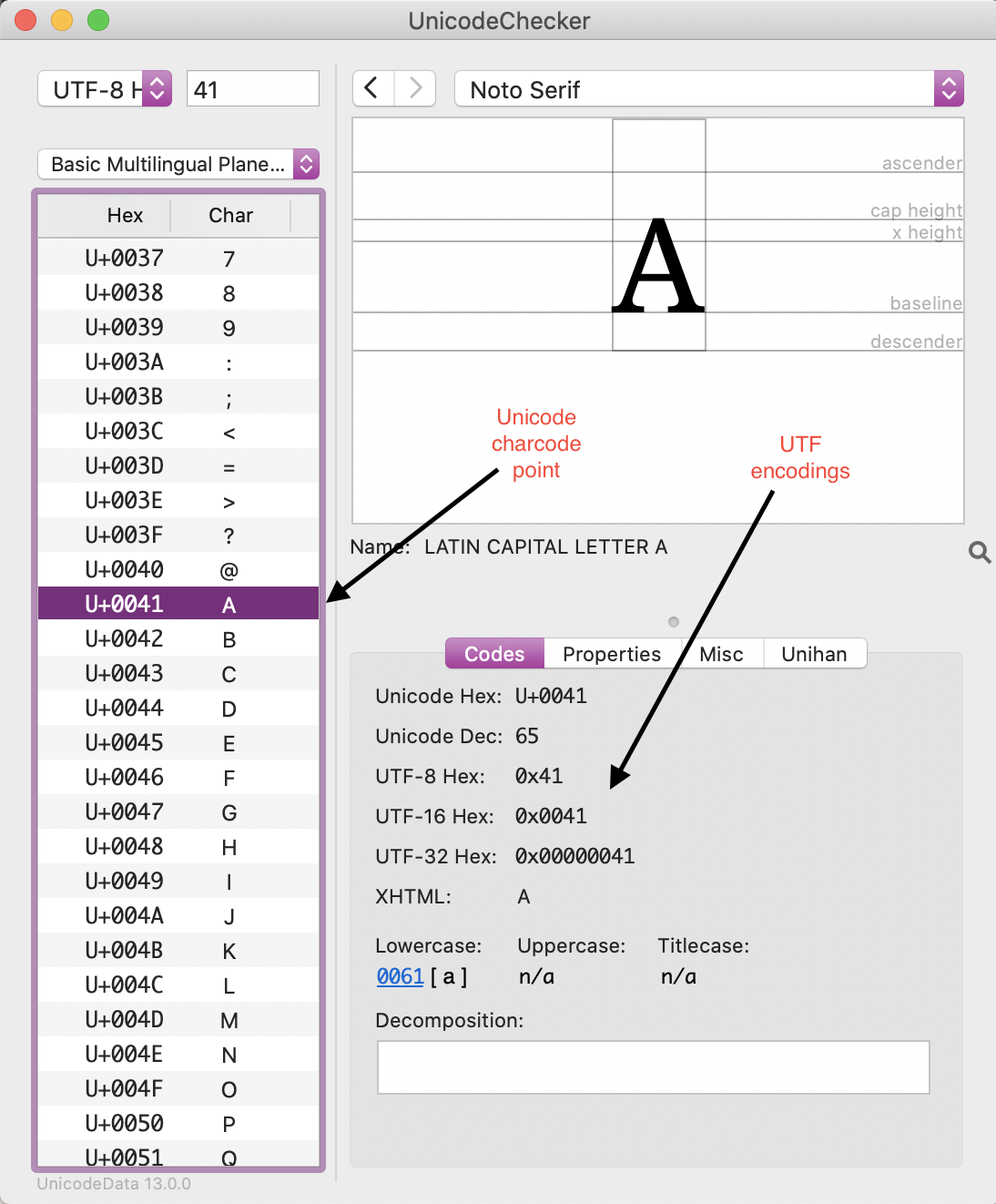
Unicode and UTF code points in UnicodeChecker
Here, you can see the familiar hexadecimal reference for upper-case a in Unicode. UTF-8 is one of three transformation formats, alongside UTF-16 and UTF-32. They differ according to the number of bytes, or units of 8 bits, they use to encode a character. UTF-8 uses between one and four 8-bit bytes; UTF-16 uses two bytes (that is, 16 bits at a minimum) or four bytes; UTF-32 uses four bytes to encode each character (that is, 32 bits).
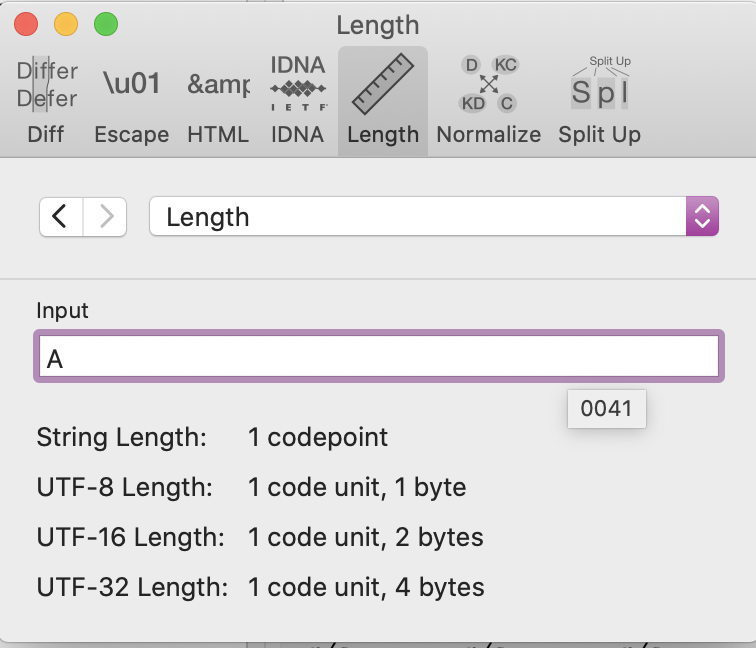
Code lengths in Unicode and in UTFs
Here again are some data for the upper-case character a. You can see that there is one codepoint or code unit in each case, but the number of bytes varies from one to four, with UTF-8 being the most economical format for simple characters in Latin script. This is one reason why today it is by far the most widely used encoding in the internet.
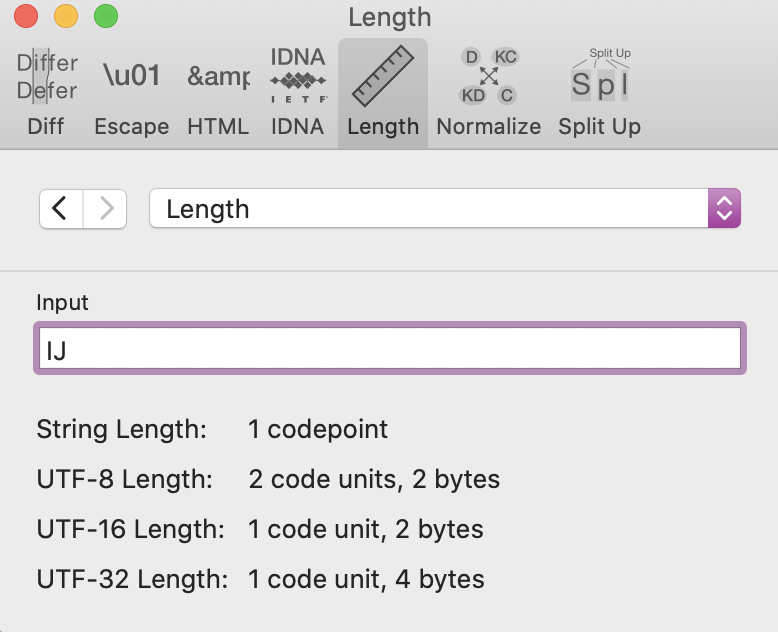
IJ: code length
By contrast, the upper-case ij digraph as used in Dutch represents a single code point and requires two bytes in UTF-8. An em-dash requires three bytes.
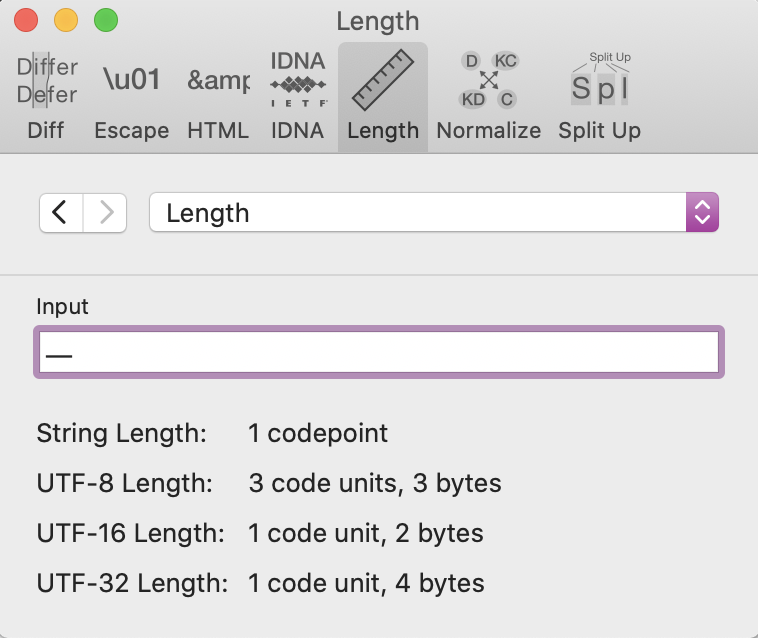
Em-dash: code length
CJK characters in UTF-8 are as a rule longer than those in Latin scripts.
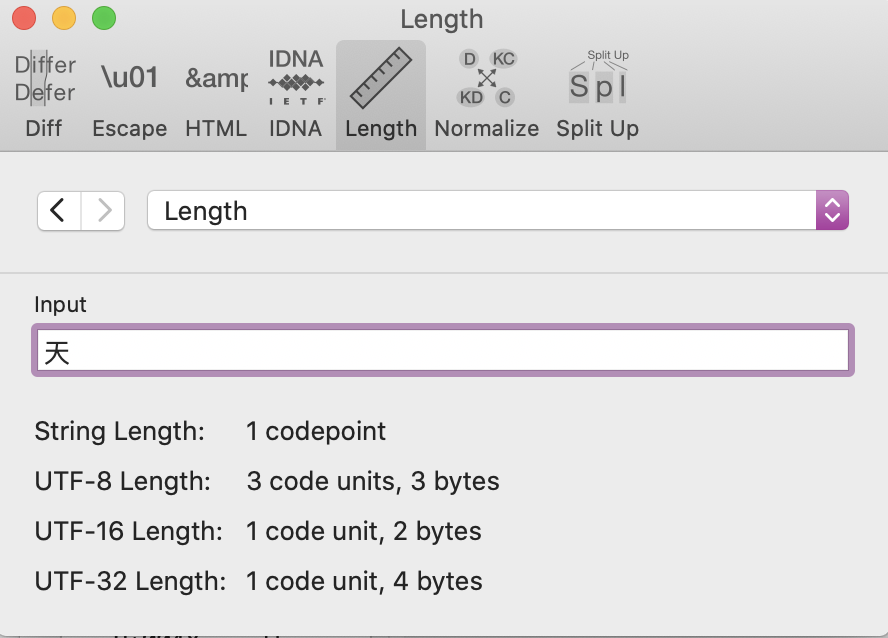
CJK character: code length
What, then, is the purpose of any of these transformation formats? It is to connect a Unicode reference-point to the purely binary encoding through which a computer operates.
Translating code points between Unicode and binary
It is in binary format that the characters you type are ultimately stored in a computer — in other words, in bits and in turn in bytes. This explains what the size of a file, and all of the data it may contain in the form of numbers, formulae or text, is likewise expressed in bytes (e.g. kilobytes, megabytes).

File size in kilobytes (k)
Transformation formats such as UTF-8 can represent any character in Unicode, which means that you can expect to be able to input any character in any script in the course of your work. The existence of a single standard and a universal encoding like UTF-8 therefore greatly simplifies your work. UTF-8 values are also much easier to handle that plain binary code would be.
3 - Unicode tools
A number of tools exist through which you can explore the relationship between scripts, languages and characters, in particular the web-based resources developed by Richard Ishida.
You can also use applications directly in your computer. The Unicode Consortium has developed Unibook Character Browser as a resource for Windows; this also requires you to download and install related character property data.
An alternative application for Windows is BabelMap.
For macOS, UnicodeChecker is a utility that is comparable in scope.
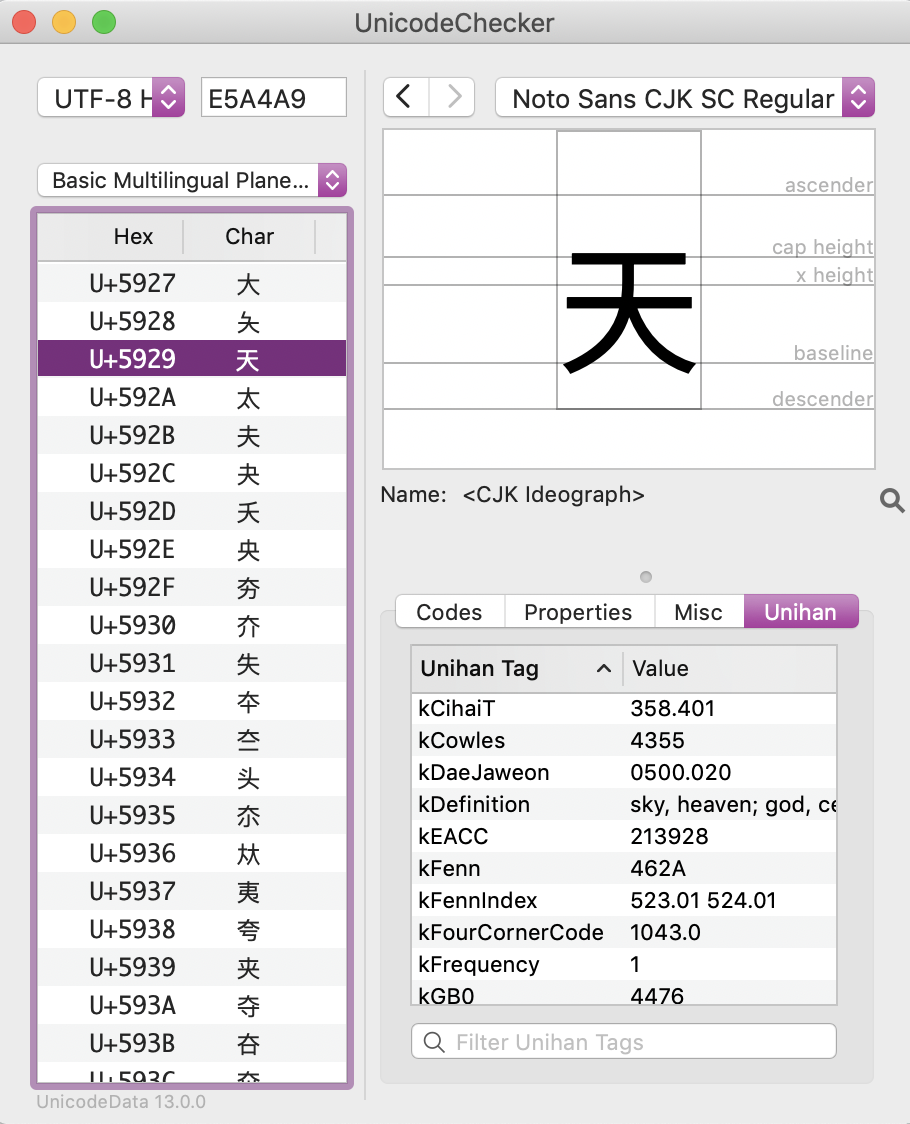
Unihan data in UnicodeChecker
For characters in the CJK blocks in Unicode, UnicodeChecker also summarizes information derived from the Unihan Database.
4 - Using the International Phonetic Alphabet
The International Phonetic Alphabetis an alphabetical system of phonetic notation. It is based on Latin script.
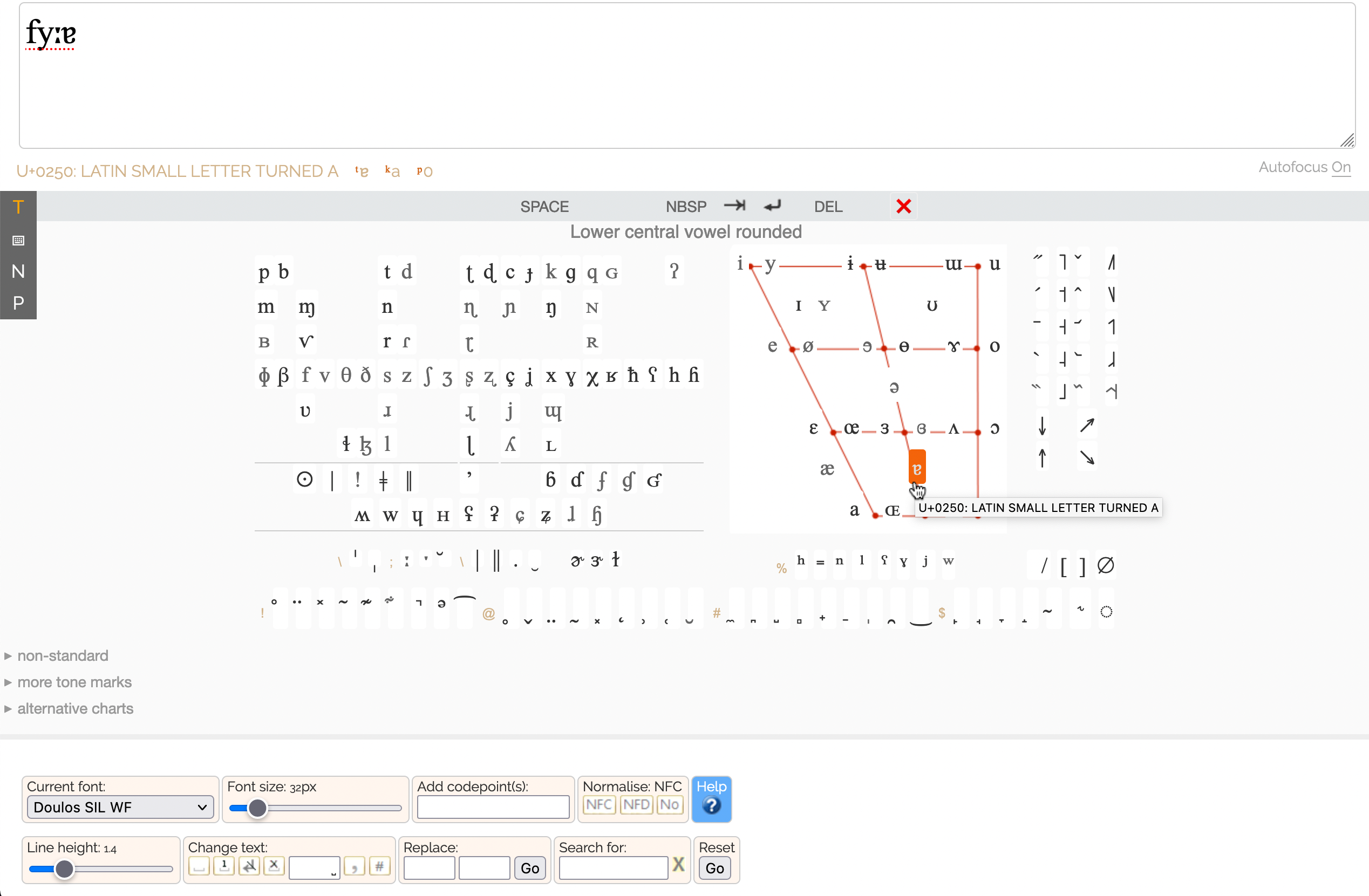
The IPA chart (source: r12a)
One convenient way to generate a phonetic transcription using the IPA is via an IPA picker: you select the symbols required and they then appear in a box at the top of the screen. Here is a transcription of the German word für. You can then, for example, copy and paste a transcription into a word-processing document.
Tip
Remember the keyboard shortcuts that you can use for copying and pasting: to copy, CTRL+C (Windows) or CMD+C (macOS); and to paste, CTRL+V (Windows) or CMD+C (macOS).When you do so, it’s important you ensure that the word-processor is equipped with a font that supports the IPA.
IPA-compatible fonts (source: r12a)
It is also possible to enter phonetic symbols directly in a word-processing application, again provided that a suitable font has been selected.
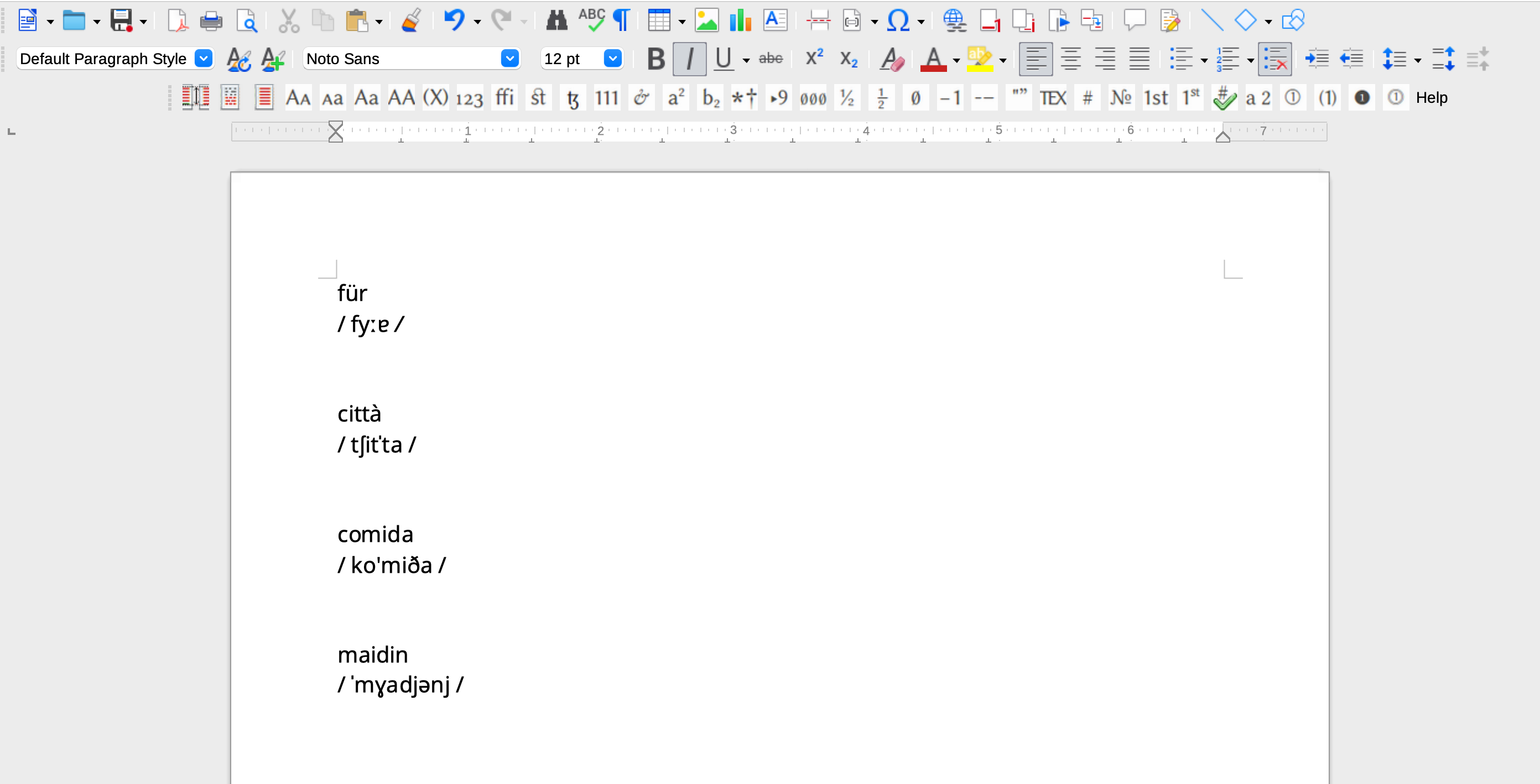
Phonetic transcriptions in Libre Office
Libre Office lends itself particularly well to this task. You can see that the transcription of the German word “für” includes two symbols, the triangular colon and the small turned a character, that do not form part of the Basic Latin script. The IPA is, however, included in Unicode and when you need to input a symbol that is not to be found in the Basic Latin block, you can click on the omega icon in Libre Office in order to select the relevant character.
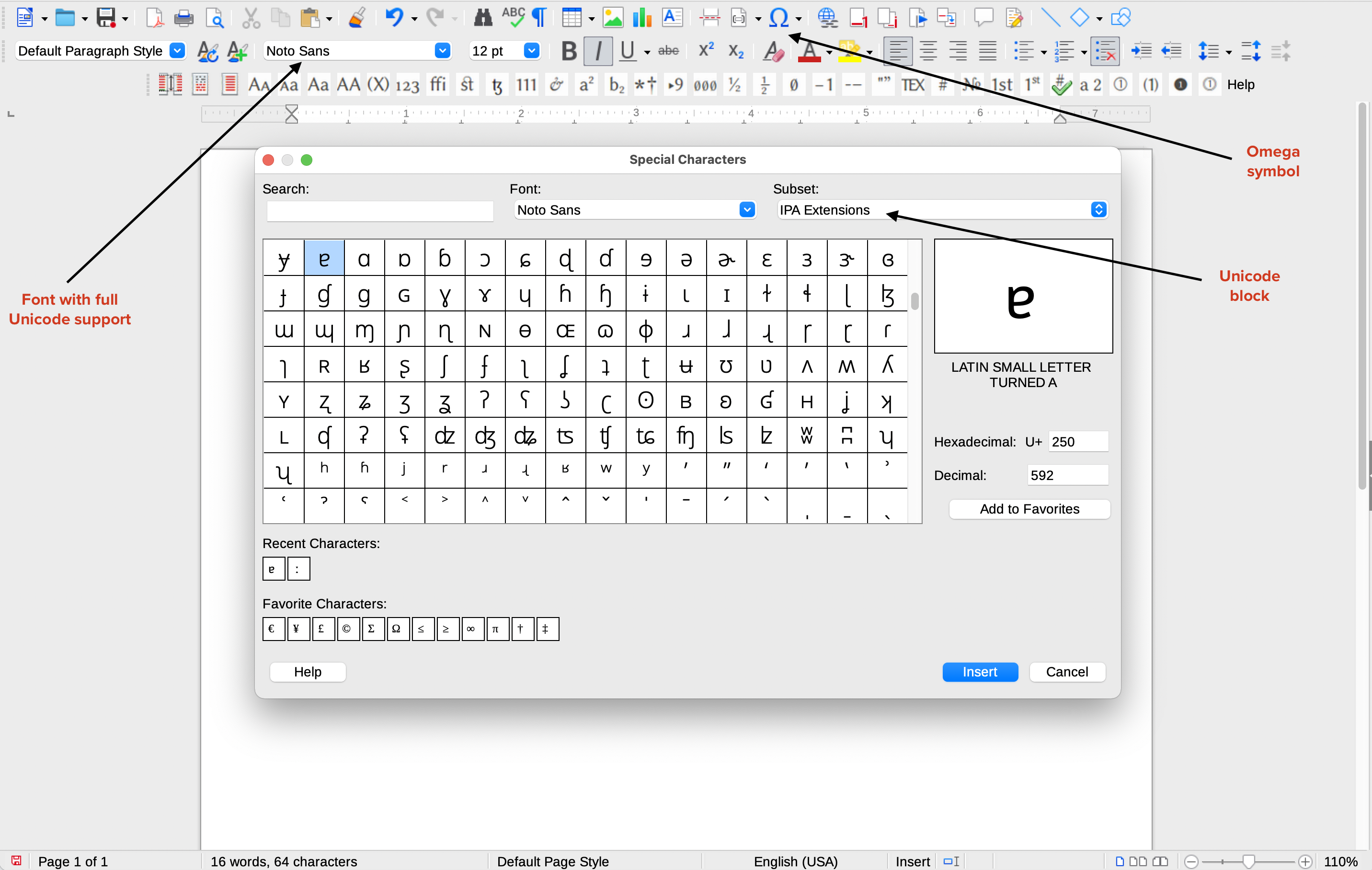
Selecting an IPA symbol in Libre Office
A panel will then open below the menu bar. Select the relevant Unicode block: in this case, IPA Extensions, and then you can insert the required symbol.